
科技论文的NLM XML文档生成管理系统
智扬依托强大的软硬件团队支持,构建一个基于 NLM DTD 的PDF 信息抽取系统。NLM DTD是由美国国立医学图书馆(NLM) 下的国立生物技术信息中心(NCBI)开发的一套更具有普遍性及通用性的学术文献XML描述规范。NLM DTD包含3个规范:文献存档标签集(Archiving Tag Set)、Journal Publishing Tag Set(期刊出版标签集)和 NCBI Book Tag Set(图书标签集),其中期刊出版标签集为全球科技期刊提供了一种通用的期刊数据交换的文档格式,可以让出版商和数据库进行期刊内容的存储和交换。目前该标准已成为美国的国家标准,且已成为科技期刊界的行业标准。
系统将科技论文转换为符合NLM DTD格式的XML文档可分为如图(一)所示步骤。操作人员拿到PDF文档后,先导出其中图表,接着在系统中维护论文如期刊名称、论文标题、作者等基本信息,再将论文正文、参考文献等内容编辑成HTML文档后,系统自动生成XML文档。生成XML之后,可在本系统验证XML文档格式与内容。操作人员最后提交至PubMed与PMC网站进行线上验证。

图 (一) 科技论文转换为NLM XML 格式的流程示意图
基于对NLM DTD分析之后,本着实现本系统功能目标为宗旨,大致可将本系统分成四部分,如图(二)所示。
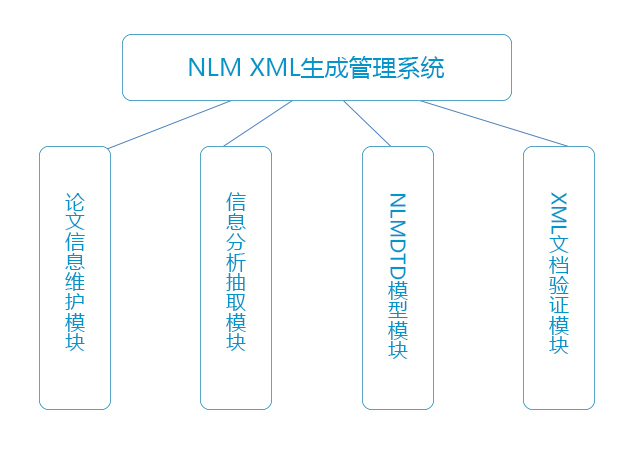
图 (二)系统功能模块结构
按科技论文的逻辑结构,我们设计将论文分解成杂志期刊信息、基本信息、主体信息、结尾四个部分来维护,如图(三)所示。我们根据内容的复杂程度设计了两种维护方式:文本资料维护与HTML格式文档资料维护。文本资料维护方式即在本系统中提供输入框让用户直接输入文字,本系统考虑到布置的方便不考虑使用数据库,所有数据以自定义的XML格式存储。
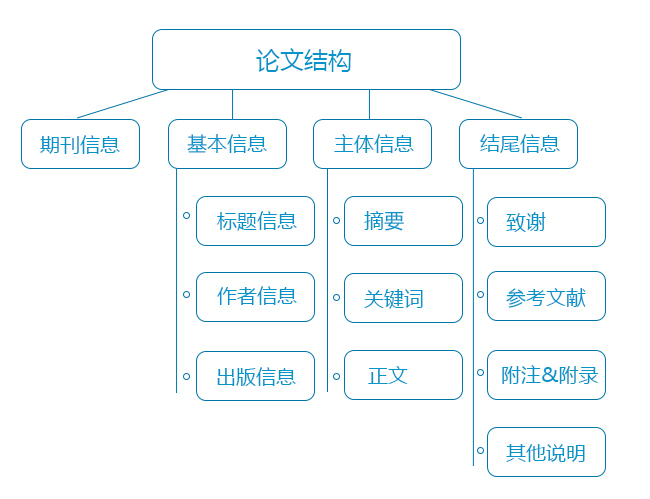
图 (三)科技论文结构
随着互联网技术的进步和人们对互联网的依赖,以及大数据时代的到来,使得HTML逐渐不能适应用户的需要,在这种情况下XML应运而生。XML已经成为Web上数据表示交换和集成的标准,因此高效可靠的存储技术成为众多的研究人员所研究的方向。美国NLM DTD的历经了十多年的变化发展,已经被业界公认为科技期刊存储和传输的标准。
虽然互联网大数据时代的到来,但传统纸质期刊依然有其权威性,PDF文档做为印刷生产过程中的文件交换标准将长期存在。加之NLM DTD发展,将PDF转化NLM DTD格式要求的XML文档存在着较大的市场需求。
从分析NLM DTD的三大规范之一Journal Publishing Tag Set 3.0入手,设计一个系统工具,让用户通过使用自己熟悉的工具编辑常见的HTML。系统应用正则表达式信息抽取技术自动将用户编辑的内容转换成NLM XML文档并提供验证机制,最终实现生成的XML文档通过PubMed与PMC的验证。
